MySQL Series: Performance Engineering – Find What April 14, 2015
Posted by msrviking in MySQL, Performance, Performance tuning.Tags: identify, mysql, mysqldumpslow, performance, performance tuning, slowquerylog
add a comment
In the post MySQL Performance Engineering series – The Goal I had mentioned about the problem statement, and how I planned to go about it. I had series of areas that I need to attend to stabilize the performance and as an old adage I went by finding those low hanging fruits that were spoiling the backyard “the queries”.
Being a first timer on stabilizing the performance of MySQL system I was looking for a way out on, how would I know which queries are doing badly? As in SQL Server we have DMVs that capture the slow performing queries, or traces which profile the database system for a set events and columns (duration), there is something similar in MySQL world known as “Slow Query log”. Luckily I had this handy information from the Dev team who were receiving hourly notifications on which queries were running slow on a particular day.
Now to more details.
Slow Query Log, what is it?
Taking the text from The Slow Query Log page which says “A slow query log has those SQL statements that took longer than these ‘n’ seconds to fetch rows after examining ‘m’ number of rows of the table”. If I remember right, I believe we had set the value for long_query_time > 3s, and default value for min_examined_rows_limit. This would mean that mysqld would write to log file for any queries, stored procedures that need attention because they are exceeding the limit of execution of 3s.
There are few other settings too that could be configured before you enable logging of slow queries into the log, and could be pored through the above link of Slow Query Log.
A sample output of what the slow query log is here
/usr/sbin/mysqld, Version: 5.6.13-log (MySQL Community Server (GPL)). started with:
Tcp port: 3372 Unix socket: /db01/mysql/mysql.sock
Time Id Command Argument
SET timestamp=1390907486;
call sp_name (412,15000);
# Time: 140128 5:12:07
# User@Host: user[pwd] @ [xxx.xxx.xxx.xx] Id: 11963111
# Query_time: 54.035533 Lock_time: 0.000000 Rows_sent: 0 Rows_examined: 204534
Please read the above sample output for key information like
Call..-> is the stored procedure name that is called
Time -> is the time of execution of the stored procedure or a query
Query time -> the time taken in seconds for the stored procedure or query to complete
Rows examined -> number of rows looked through during the queries execution in the stored procedure
So what do you do with this raw data? I would think of running a utility that will read through the entire log and give me a summary of what is logged. Well, if I had to do this manually I would have had to use my brains stressed to a level of finding a right app, script, test, review (in cyclical pattern) and abstract the results out. I had been lucky here to and hadn’t spent that much time and effort. The next section will describe of what I did.
Raw data of Slow Query Log, what next?
In the above sub-section you would have noticed the output of the slow query log which is Raw, and information rich. Now, to get a decent report of the raw data I had to use the utility “mysqldumpslow” provided by MySQL. Mysqldumpslow is a perl (.pl) program that parses the slow query log and groups similar queries except if data values are different. More here on this nice little program. I didn’t use any additional parameters to parse through the log, and one could tweak the values of the options listed.
I had to do one more thing “Install a perl engine” before I could run the mysqldumpslow.pl in its location in my system. And then, I had to copy the raw slow query logs to the folder that standalone .pl file, and run the command mysqldumpslow through the command prompt in the path.
The output looks like this
Count: 2 Time=57.39s (114s) Lock=0.00s (0s) Rows=313.0 (626), user[pwd]@[xxx.xxx.xx.xx] || SELECT * FROM t WHERE col = ‘S’
Count: 617 Time=57.33s (35371s) Lock=0.12s (76s) Rows=1.0 (617), user[pwd]@4hosts || SELECT * FROM t1 WHERE col1 = ‘S’
Count: 713 Time=56.26s (40116s) Lock=0.72s (516s) Rows=1.0 (713), user[pwd]@4hosts || SELECT * FROM t4 WHERE col2 = ‘S’
Count: 3 Time=55.02s (165s) Lock=0.00s (0s) Rows=1.0 (3), user[pwd]@2hosts || select t1.col1 from t1 join(t2) where t1.col4 !=N and t1.col5=N and t1.col1=t2.col1 and t2.col2=’S’ and t1.col3=N
The above sample output has
Count -> number of times the query was called at that instance
Time in () -> total response time in seconds
Time not in () -> average response time in seconds
Lock in () -> total locking time in seconds
Lock not in () -> average response time in seconds
Rows in () -> rows examined
Rows not in () -> rows sent
User, pwd and hostname /host ip address -> speak for themselves
Query definition -> query that was executed with response time, lock time, rows examined, and sent
Please note the two | “||” after the query aren’t from the mysqldumpslow.pl. I had to modify the .pl file to include the || for bringing the line of output into single line, else I would have had a /n (enter character) after the hostname /ip. I wanted to pull all the data into one single line, and convert text to columns in excel for better readability and analysis.
Now the slow query log is formatted from the utility and it’s to be analyzed, and that wasn’t difficult as much figuring out on how to format for better reporting.
Analyze the Slow Query log
Here is the sample report I had to put in excel for better analysis
| Query Profile | ||||||
| Calls Count | Average Time (s) | Total Time (s) | Row Lock (s) | # Rows Sent | #Rows Examined | Query Text |
| 11391 | 43.47 | 495193 | 0.00 (2) | 1 | 11391 | StoredProcedure |
| 3757 | 34.77 | 130632 | 0.45 (1695) | 418 | 1570426 | Query 1 |
| 1788 | 14.42 | 25779 | 0.29 (514) | 1 | 1788 | Query 2 |
| 1684 | 48.6 | 81849 | 0.04 (73) | 1 | 1683 | Query 3 |
| 1117 | 52.14 | 58244 | 0.12 (137) | 1 | 1117 | Query 4 |
Are there tools that could help you summarize all these, well I haven’t used any but yes there is one I have kept learning from here.
I decided to look for queries that had least calls count, and highest average or total response time. This was the onset of my performance engineering the MySQL systems for a single goal.
Happy reading.
Blog title doesn’t match with the content March 24, 2015
Posted by msrviking in General, Uncategorized.Tags: blog, content, title
add a comment
No surprises here.
Although my blog title says My Love with SQL Server I still might have to write posts on different database technologies I am learning and getting passionate above. If I am not on top of SQL Server directly, I would be working upon something related to data for sure. And whenever that happens I am supposedly to blog on how that one thing can be done in SQL Server too.
So, happy reading.
MySQL Series: Performance Engineering – The Goal March 24, 2015
Posted by msrviking in MySQL, Performance.Tags: engineering, goal, mysql, performance tuning, plan
add a comment
This post has that one line of description as the goal for performance engineering assignment I had to work on, and about the plan on how I went about. The statement says “Ensure we have acceptable performance in the DB for 5000 concurrent users.” I knew what was waiting from me with this one line statement.
And with no delay, I had put up the plan that would touch the performance soft spots of the MySQL system. I wasn’t sure how much performance improvement will be achieved to scale the system after touching these areas.
Here is what one would want to address, and I believe this will help as reference always.
The table consists of Areas to be looked into, Dependency as in inputs from the team or system for me to assess and the priority of each Area.
| # | Areas | Dependencies | Priority | ||
| 1 | Identify poorly performing queries and all application queries | ||||
| 1.1 |
Assess the query performance |
Query list | High | ||
| Plan | Queries parameters | High | |||
| Concurrency | Access to the latest production DB in Dev environment | High | |||
| 1.2 |
Assess the table performance |
Information on business (application) purpose of the query – application perspective | |||
| Index | Inputs from existing query benchmarks – production or performance testing environment | High | |||
| Partition | Medium | ||||
| Structure | Medium | ||||
| 2 | Identify configuration parameters | ||||
| 2.1 | Assess the impact of existing configuration parameters | Configuration parameters in production | Medium | ||
| 2.2 | Recommend new configuration parameters | Architecture setup of MySQL instances in production | |||
| 3 | DB scaling (Up & Out) | ||||
| 3.1 | Assess the current performance of Hardware and MySQL | Current hardware setup of MySQL instances | Medium | ||
| 3.2 | Propose additional hardware based on findings | Architecture setup of MySQL instances in production | Medium | ||
| 3.3 | Propose change in MySQL architecture | Medium | |||
I had to follow this plan all throughout the assignment for project management reporting, tracking the progress, and at the end quantifying the % of performance improvement in each area.
Not to re-emphasize the intent of having this plan is to work bottom-up. The work had to start from query, index, tables, database, instance, and hardware which is the standard for any performance optimization. The following posts would be on most of the above line items.
Happy reading.
A year and more gone by..no posts March 23, 2015
Posted by msrviking in Configuration, Data Integration, Design, Integration, MySQL, Oracle, Performance tuning.Tags: best practices, Design, learnings, mysql, Oracle, performance, tuning
add a comment
I alone know on how I have missed blogging on what all I learnt on MySQL and Oracle RDS over last 14 months, and how much I wished that what all I did was on SQL Server. Well, not always it is the way you want it to be.
There was such a learning over this period on the way things are done in MySQL, Oracle at design, development and performance engineering that I might have to spend several days blogging about. In next few weeks to months I will be spending time on variety of learnings starting from design, coding, through performance tuning to achieve concurrency and scalability. Although these topics will primarily be around MySQL, Oracle I might map on some of the done work to SQL Server features and implementations.
A brief preview on what would be the topics on, and possibly will be having its own sub-series in detail with mapping
MySQL:
- What are the physical design checklist
- What are best instance level configurations
- What are the optimal working configuration values of host hardware and OS
- What are the ways to optimize execution plans
- What are the coding best practices
- What are the ways to troubleshoot deadlocking problems
Oracle RDS:
- What are the best practices for coding in PL/SQL
- What are the best practices for designing and building integration DB
- What are the ways to optimize execution plans
- What are the ways to monitor for any performance bottlenecks
- What are the ways to achieve concurrency, scalability and performance
- What is that not do-able when compared to on-premise instances
- How to administer the instance
Happy reading.
What am I doing now-a-days over last few months..? January 30, 2014
Posted by msrviking in General, MySQL, Performance tuning.Tags: architecture, mysql, performance, sql server, tuning
add a comment
I had been busy doing stuff on SSIS for few months, then on MySQL from the last post I have put up in the blog. What is that I am doing on MySQL and writing a post on a SQL Server blogging site? Well, I am kind a trying to get hold on how MySQL works, while I am trying to stabilize the performance of system. Surely I am not a MySQL geek to look at OS, Hardware, MySQL configurations deeply, but with little knowledge I had and gaining as time is going by I am trying to troubleshoot performance of the queries, indexing, and partitioning tables. These are the few things that I have been trying to put in place even before I get on other levels of performance engineering.
A thread is already on if I could shard the database, introduce read-write splitting to provide a scale-out solution by using out of the box features like MySQL cluster or customizing by partitioning tables, sharding them into different nodes, read-write splitting using MemCache.
These are lot of thinking in terms of MySQL but then I don’t have such flexibility in SQL Server although there are some implementations that use read-write splitting, using load balancers at application level and not database. I am highlighting some of those that are not there in SQL Server, and available to be used at fullest in MySQL. But then there are many of those missing in MySQL which is so good to use and work out things in SQL Server.
Some of the ones that I am missing MySQL badly are
- Profiler
- Graphical execution plan
- Indexes with include
- Free and easy to use monitoring tools for OS, Hardware
- Multiple query plan algorithms
- Proper documentation (implementation or bugs)
This post is to share what I am seeing those top few things in MySQL and few things that I am missing when I think of SQL Server. It’s kind of missing or home-sick post I would say.
I will keep writing as and when I learn new thing and definitely put a comparison with SQL Server features.
Happy reading.
RIP MCM……my mourning September 4, 2013
Posted by msrviking in Career, DBA Rant.Tags: Certification, MCM, Path, Program
add a comment
I didn’t want to write on this sudden happening, but then I couldn’t hold my anguish after reading so many posts, articles, and I thought I should share my quota of wailing. Two things broke my decision – an InsiderMail from Paul Randal (@PaulRandal | Blog) on 9/3, and the post from Satya (@SQLMaster | Blog) on 9/3. Both the industry experts came up with their feelings on the sudden happening, coincidentally on the same day.
MCM is discontinued and this is what gave me a shocker, a stunner. This post talks about on how Microsoft has decided to get it off its list. I kept spending few hours reading different articles, posts, news online, news feeds with the key words MCM and realized I am hearing, and actually bearing the brunt of the fact that Microsoft has decided to retire the MCM program. If I have to be honest to myself, I was trying hard to get closer to my dream and goal of obtaining a MCM. Now looks like I wasn’t getting anywhere near, apparently, when something has holding me back – retirement of MCM on 1-Oct-2013. Not a good news at all for folks out there who have probably dreamt like me, and put in more hours to get one or trying to get that ultimate achievement. Microsoft has denied that feeling to all those fans of SQL Server who worked years on the product, by just snubbing with a pull-off-the-plug action, on the program. The death of MCM is going to be quicker than retiring the famous reader – Google Reader. It took Google few months to bring down the service, and Microsoft is going for the death-punch in less than 2 months, huh. A known play as usual, and one without any breather by Microsoft. Nice job, uh.
I could go on ranting my displeasure and disappointment on the news, but then what’s the use of crying for what has happened. The work would get back to usual after few days everywhere, and everyone will visit their priorities. However someone has to keep up the fire and choke the guys who have done this abrupt thing. So go ahead and please, please vote up for a connect item on MSFT website created by Jen Stirrup – a SQL Server MVP protesting and asking back the MCM program.
One last thing – another blogger has shared his displeasure on this post, and made sense to me http://michaelvh.wordpress.com/2013/08/31/microsoft-is-retiring-the-mcsmmca-program/
If you happen to read this post, please share with as many as possible so that there is movement to reverse the decision or probably come up with something better than MCM at least. Don’t forget to vote-up if you don’t want to share this post.
Thanks for reading the bereavement news.
Sad Feeling – Shyam Viking.
SSIS is for ETL, ELT or EL….clamor continued September 3, 2013
Posted by msrviking in Business Intelligence, Data Integration, Design, Integration Services.Tags: configuration, data, EL, elt, etl, integration, Integration Services, SSIS, synchronization
add a comment
In my yesterday’s post I had mentioned that we had to design and implement a SSIS solution that does EL, and had my own gripe about addressing only the non-functional requirements. Also it was just about a process of extraction & loading – EL.
Today let me start off with the definition of ETL, ELT, and then the new word with EL where T is missing, or supposedly not to be considered here. While writing this post I realized I should put across few notes on what an ETL or ETL means, or probably the differences between these implementations. I could have probably listed the points as a neat comparison table but blame it on my laziness that I am sharing these links. Trust me I have read these links, and I completely acknowledge the technical content’s relevance to ETL vs ELT.
http://www.dataacademy.com/files/ETL-vs-ELT-White-Paper.pdf
http://blog.performancearchitects.com/wp/2013/06/13/etl-vs-elt-whats-the-difference/
At the end ETL would mean that you have a powerful infrastructure in your destination, to handle transformation using SET operations, but then you would need a staging area to do the transformation and push the data into the destination tables. Whereas in ELT processes, the tools have the power to do the transformation in parallel infrastructure setup and in-memory, and away from the destination systems. After the data is transformed it is loaded into the databases for business to consume.
So having these principles in mind, we had yet to implement the EL instead of ETL or ELT. I personally didn’t find the approach to be good to implement, and which could have been done easily without any development effort using a CDC for Oracle in SQL Server, Replication. However I found some finer pros of this approach, and I remember noting those in one of my earlier post over here. Those few are,
-
SSIS doesn’t need any additional changes to be done on the source end, except that we configure a connector to pull the data.
Whereas Replication from Oracle had to create temporary tables, triggers in the source schema which probably is an overhead along with changes on the source schema. This is not definitely acceptable by any business or system owner. CDC for Oracle in SQL Server helped to a larger extent to address the above problem, but then enabling certain properties of the source instance would be overhead for security considerations.
- SSIS is essentially for a flow-control of data, and we could synch data on a pre-set precedence of steps. For example the master table’s data should ported first, and then the transactional tables.
- SSIS could be configured to pull data from the source based on business criteria by using parameters in the WHERE statements.
- SSIS gives finer control on error logging, handling and of course we could have retry packages to pull in data of failure.
- SSIS also gives me a perfect control on the defensive programming so that all business data is in place.
- SSIS could be tweaked, tuned to have optimal performance from extraction through loading.
Overall we will have control on what is happening when the data is extracted and loaded. Now I am wondering all these are perfect design guidelines for any ETL or ELT, and how I wished or rather would have not wanted on just an EL process, huh.
Cheers!
SSIS for Extraction & Loading (EL) only September 2, 2013
Posted by msrviking in Business Intelligence, Data Integration, DBA Rant, Design, Heterogeneous, Integration, Integration Services.Tags: configuration, Data Integration, EL, extraction, factors, implemnetation, integration, loading, rant
add a comment
There were series of posts earlier on the different ways to pull data from Oracle to SQL Server where I shared on how to port data either through Replication, CDC for Oracle, and few others like SSIS. I thought I will give a starter to a series of post(s) on how we went about picking up the option of implementing SSIS as a way to bring data from Oracle to SQL Server.
The major drivers (business and non-functional) for picking the solution were
- The destination database on SQL Server should be replica of the source
- No business rules or transformation need to be implemented when data is pulled
- The performance of pull and loading should be optimal with no overheads or bottlenecks either on the source or destination
The destination system was mentioned as ODS, but it surely isn’t the same as Operational Data Store of DWH systems. Sadly the naming convention had been adopted by the shop where we had to implement the solution, and you might see me using the word ODS for sake of explaining the implementation, and I am sorry for putting the incorrect usage of the word. You would probably see little more of conventional or standards being skewed in the implementation, and of course a bit of my comments on how this could have been handled, better.
So the ODS was to hold data that would be used by downstream business analytics applications for the business users, with an intent of providing Self-Service BI. The ODS is to be of exact – in the form of schema, and data as in the source. The job was to pull data from the source without any performance overhead, and failures. Not to forget to mention that there needn’t be any transformation of data. At the end we use SSIS as only an Extraction & Loading tool instead of ETL – Extraction, Transformation and Loading.
This sounds simple, eh, but beware this wasn’t that simple because the design was to be kept simple to address all of the above factors. The SSIS package(s) had to handle these at a non-functional level,
- The package should be configurable to pick and pull data from any set date
- The package should be re-runnable from the point of failure
- The package should have configurability to address performance needs – package execution time should be less, the source should not be overloaded, the destination should be full in its efficiency while data is loading.
- The package should be configurable to pull data from source in preset chunks. The preset chunks could be based on a period basis – days /months /years, or number of records per period
- The package should have the option to flag any other dependent packages to run or not run during initial and incremental loads
- The package should have defensive design to handle bunch of different type of errors
- The package should have error logging and handling at a package level, and at record levels
In Toto this solution was more to how do we design for the non-functional requirements and implement, leaving the functional side of the data. This type of implementation is half-blind and I will talk more on those cons we had to face, when I get in to details of each implementation.
A post after few weeks of gap, and one with learnings and summaries on how it could have been better.
SQL Server 2012 CDC for Oracle July 5, 2013
Posted by msrviking in Architecture, Change Data Capture, Configuration, Data Integration, Heterogeneous, Integration, Integration Services, Oracle.Tags: CDC, Change Data Capture, data integartion, Data Synchronization, RAC, sql server, SQL Server 2012
add a comment
Sometime in June 2013, I had to work on an alternate option to Replication to replicate data from Oracle to SQL Server 2012. The primary requirements were
-
There should not be performance impact on the Oracle instance, and the CDC should work seamlessly with a RAC setup having multiple log file locations, and reading any DML changes invariably where the transaction happens (different nodes of the Oracle RAC)
-
There should not be any additional objects (temporary tables, triggers) that should be created in Oracle instance unlike to what happens in Replication setup
-
The DDL changes on the source should be manageable with appropriate configuration
Keeping all this in mind I brought up CDC for Oracle in SQL Server 2012 as the next best option and built a POC. As a result of the POC I had documented the whole of the steps or probably the implementation picture of the POC for my future reference. Today I decided to share it with you all so that you too could benefit the implementation.
So here goes the excerpts from the document. Sorry couldn’t convert the document into blog style, though.
Cheers and Enjoy.
Change Data Capture (CDC)
Overview
Change Data Capture (CDC) is way of tracking and capturing changed data on real-time basis.
The data changes because of DML operations like insert, update, delete these are logged into log files of the source database. The log files serve as input to the capture process which runs asynchronously. The capture process reads the log files and adds the change information to the tracked tables that are associated with the respective source tables.
The below diagram (as represented in MSDN) summarizes the process of change data capture.

The data captured in the tracking tables is consumed by SQL Server Integration Services to refresh the end business tables in an Operational Data Store (ODS).
Internals of SQL Server 2012 CDC for Oracle
The capabilities of change data capture is to read data from data sources and synchronize the data changes incrementally from source to target tables, and is real-time.
The Change Data Capture for Oracle setup has these components
Oracle Database Instance
The data changes happening on the Oracle source tables are captured into redo log files, and these redo log files are archived for reading by Oracle LogMiner.
The Oracle LogMiner reads the archived redo log files if the Oracle databases
-
Archived log mode is enabled
-
Supplemental logging is enabled
CDC Service & CDC for Oracle Designer
SQL Server 2012 has the new feature called SQL Server 2012 CDC for Oracle and is available as part of Service Pack 1 (SP1). The CDC feature comes with two installable as part of the SP1, and these files install CDC Service Configuration, and Oracle CDC Configuration utilities.
Console for CDC Service
A pre-requisite before creating a CDC service is to have a system database called MSXDBCDC created on SQL Server instance. The database is created by executing the step Prepare SQL Server through the CDC service configuration console. The database consists of tables that help in storing the configured databases, services and trace (diagnostics) information.
All CDC operations use the CDC service to synchronize data, and the service is created as Windows service. The CDC Service management console is used to configure CDC service however CDC services could be configured and run on any server, other than the ODS or Integration Services (IS) systems. Also more than one CDC service could run on a dedicated system.
Designer console for CDC for Oracle
A CDC for Oracle instance is configured under a CDC service, and multiple CDC instances can be configured against an Oracle database using the CDC designer console.
A CDC instance for Oracle
-
Has a connection string to Oracle instance. The connection string is configured against scan IP name, or VIP name
-
Has multiple source tables (with respective primary keys) and with selected capture columns. Each source table with capture columns has a respective supplemental logging script which is executed on the Oracle instance. The supplemental logging on the table captures the data changes on the columns into redo log files
-
Creates a CDC enabled database on SQL Server
-
Has an option of enabling advanced properties like cdc_stop_on_breaking_schema_changes, or trace. These properties help in managing the instance behavior upon a schema change in source table, with additional diagnostics for troubleshooting any issues
SQL Server
CDC enabled database
A CDC instance creates a CDC enabled database and each of this database has multiple mirror tables, capture instances or tables representing each source table, and the system tables that provide information on the change capture objects, columns, DDL history, health of the CDC instance.
The CDC enabled database is by default created with case sensitive collation, and could be changed by modifying the database deployment script created by the CDC instance designer.
Mirror tables
Each source table in Oracle has a mapping mirror table in CDC enabled database in SQL Server. The mirror table is a similar copy of the source table, except the data types and length which are different in SQL Server. Any schema changes on the source table is verified by CDC process by checking against schema of the mirror table.
The mirror tables are always empty, and should not be used for as business tables. The mirror table is identified with a specific schema owner, and are not created under default dbo schema.
A sample name of mirror table is CDC_POC.CDC_POC_DEPT.
Capture instances
Each source table has a capture instance, and the capture instance is created as system table. The CDC process populates capture instances with data that is changed in source. These tables has columns that represent the source or the mirror table, and columns that store the Start and End Last Sequence Number (LSN), a sequence value, type of operation and update mask.
Here is the sample structure of a capture instance
|
Column Name |
Purpose of the column |
|
__$start_lsn |
LSN associated with the commit transaction of the change. |
|
__$seqval |
Sequence or order of rows that the transaction has affected. |
|
__$operation |
The type of DML operation 1 – Delete 2 – Insert 3 – Update (old value) 4 – Update (new value) |
|
__$update_mask |
Bit mask of the column ordinals |
The capture instance always has schema identifier as cdc, and ends with _CT.
A sample name looks like cdc.CDC_POC_DEPT_CT.
The capture instance has the information based on the DML changes that are committed on the source table. This table provides inputs in the form changes (data that is changed, columns whose values have changed, and the type of change) for SSIS packages to refresh the business tables.
The capture instance could increase in size based on the changes that are captured from the source. This table could be purged on regular basis in order to keep the size of the table and database per standards.
Business tables
The business tables contain the data that is used by the business applications. The business table should be created with any standard naming convention and could be created in any other database, and need not be in CDC enabled database. The database can be hosted on any other SQL Server instance.
The schema structure of the business table could be same as source or mirror table but the data types could vary. If the data types are different then the SSIS packages should have appropriate data type conversions.
The business table is initially populated through SSIS as a full load, and then the incremental loads are applied to refresh the data. The incremental loads fetch the data changes from the capture instance tables, and does an insert or merge operations on the end tables.
Overall process
The overall CDC process is summarized in the below diagram.
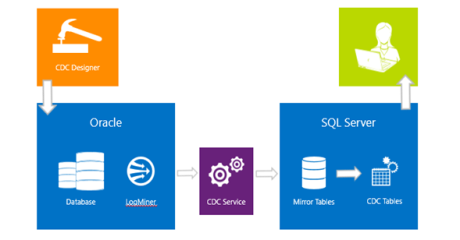
The CDC service fetches the data changes from the Oracle source table. The CDC service connects to the Oracle database instance and invokes the Oracle LogMiner. The CDC process requests the LogMiner for the data changes that have been committed on a source table. The LogMiner starts the data fetching process from the archived redo logs, and returns the changes against columns that are enabled with supplemental logging.
The CDC service then populates the changed data into capture instances along with last sequence number, data that is changed in a column, and the type of operation.
The CDC service uses the CDC instance information to connect to an Oracle instance and to fetch data changes in particular source table for the specified columns.
Implementation Scenarios
Data Synchronization – Connecting to Load Balancer
The below diagram summarizes on a scenario where the CDC for Oracle instance is configured to Oracle RAC through the scan IP name.

Oracle Cluster
The Oracle instance is in a RAC configuration mode, where Node 1 xxxxx01.xxxx.net) and Node 2 (xxxxx02.xxxx.net) are load balanced and is connected by using a scan IP. The two nodes share the same storage area, and the redo log files generated by these nodes are archived and stored in file locations in the storage area. There are multiple file locations, and each location is created based on the day, month and year. Each folder could have multiple archived redo files.
SQL Server
The SQL Server system hosts CDC service and CDC Designer for Oracle tools.
The CDC service is created using the CDC service management console and is run as Windows service using Local System account.
The CDC for Oracle instance is created using CDC designer console. The CDC instance connects to the Oracle instance using the scan IP name – xxx-rac01-scan.xxxx.net. The CDC process reads the archive logs using LogMiner and writes to the CDC enabled DB. The data changes that are captured are written into the capture instance in the SQL Server.
The mirror tables are empty and are never populated either during the full load initially or during the data refreshes through incremental load.
ODS
The business tables are created in the operational data store, and the table is populated with full load from the source for the first time. The data changes captured through the CDC process is applied on this table through incremental loads.
SSIS
SQL Server integration services (SSIS) runs on a different system. The purpose of having SSIS is to perform a full load into the business table initially, and when the CDC synchronization is set the data refreshes happen on the business tables in the ODS.
There are two packages that perform the full load and incremental load. The below tables summarize the component used, purpose of each component, and the overall process executed by each package.
| Package Name |
Component Used |
Purpose of the component |
Purpose of the package |
| Initial Load | Execute SQL Task | Deletes the data from the business table before a full load | The package is executed only once as a full load, and when the CDC is setup or re-configured. This package deletes the destination business table, and populates latest data from the Oracle source table using Oracle Connector. After the data is populated from Oracle to SQL Server business table in ODS, system table cdc_state is updated with a LSN value that is referenced as next starting point to read the data changes from the capture instances. |
| Data Flow Task | Populates data from the Oracle source table into business table using Oracle connector from Attunity | ||
| CDC Control Task | Sets a LSN value in cdc_state (a system table created when the package is executed) table as a bookmark. This value will be referenced by the incremental package for reading changed data | ||
| Incremental Load | CDC Control Task | The task reads the last saved LSN value in cdc_state, and marks the process as start fetching data from the capture instance | The package is executed after the first initial full load. The package could be scheduled to fetch the data changes and refresh the end business table in ODS. The CDC source components marks the processing range of the data based on the last saved LSN value. The data is inserted in case there are new rows through the OLE DB destination task, or updates or deletes through OLE DB command. After the data refresh is complete on the destination table, the process is marked as completed the latest value LSN value is saved into cdc_state. |
|
Data Flow Task |
The task reads the capture instance for All or Net data changes using CDC Source component from last LSN value saved in cdc_state. The CDC Splitter component splits the data read from CDC source into three different operations – Insert, Update and Delete. The CDC splitter directs the data based on the DML operation – To INSERT into OLE DB connection; To UPDATE and DELETE into OLE DB command. |
||
|
CDC Control Task |
This component marks the end of reading the data, and the state of the reading, populating data into business tables. |
Data Synchronization – Connecting to RAC Nodes
The below diagram summarizes on a scenario where the CDC for Oracle instance is configured to Oracle RAC through the VIP names (individual nodes).
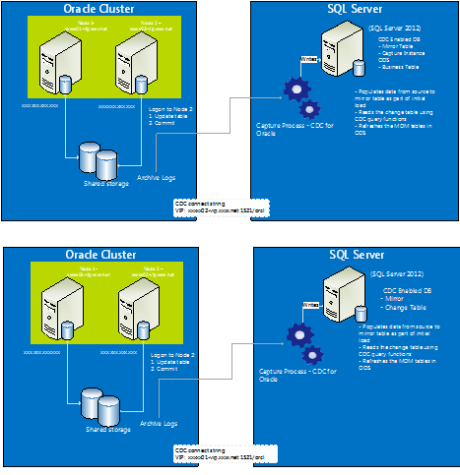
This section describes on an approach adopted to verify SQL Server 2012 CDC for Oracle works with Oracle RAC nodes, and multiple redo log files in different locations.
The first and second diagram above show that Oracle CDC instances are connected to Node 1 (xxxxx01.xxxx.net) through the VIP name xxxxx01.xxxx.net:1521/orcl and Node 2 (xxxxx02.xxxx.net) through the VIP name xxxxx02.xxxx.net:1521/orcl respectively. The CDC for Oracle reads the changed data from each node that is committed independently on each node.
As part of verification the following steps were executed
On Node 1 or Node 2:
-
Logged onto to Oracle nodes using the connection string uname/pwd@ xxxxx01.xxxx.net:1521/orcl or uname/pwd@ xxxxx02.xxxx.net:1521/orcl
-
Ran a SELECT query against a sample table under the same schema and captured the existent data in the table for validation, later
-
Ran DML (UPDATE, DELETE, INSERT) statements on each node, and committed the transaction
-
Validated the DML changes done on each node, by running SELECT statements
-
Verified if the CDC instances were capturing the changed data by running SELECT statements on capture instances
The result after these steps was that CDC instances (configured against each node) were reading the DML changes done on each node, and is captured in capture instances on SQL Server.
The above result concludes that CDC for Oracle works with RAC environment where in data is read, invariably where the transactions are committed. This also confirms that CDC for Oracle instances captures data changes that are logged into multiple archived redo log files, in multiple locations.
The key to above conclusion is that CDC process fetches the data changes by calling the Oracle LogMiner which in turn reads the multiple archived redo log files in different locations.
The captured data in the capture instances is refreshed onto business tables using the incremental package process as described in section SQL Server under SSIS.
Schema changes
This section explains on the DDL statements that impact on the Oracle CDC instances, and steps to apply the changes on the destination database.
SQL Server 2012 CDC for Oracle does not propagate the schema changes on Oracle tables to SQL Server. However enabling an advanced property named as cdc_stop_on_breaking_schema_changes helps in capturing accurate and consistent data or latest data. This property could be set under each CDC instance under Advanced Properties tab.
The values that could be set against this property are 0 and 1. On the event of schema change on Oracle source table, and when the value of cdc_stop_on_breaking_schema_changes is
-
Set to 1, then the data capture is stopped and this helps in capturing consistent data, with exceptions in few scenarios
-
Set to 0, then the corresponding capture instance in SQL Server is dropped, and this helps in capturing latest data
If the schema changes are pertinent on the source, and if these changes should be propagated to capture instance in SQL Server, and the business table then a series of steps have to be considered.
The below table summarizes different DDL statements with its impact on the CDC instance capture process, and way to mitigate the schema change.
|
Type of Schema Change |
Impact and corrective steps on schema change |
| Adding a new column to the source table | Impact: If the cdc_stop_on_breaking_schema_changes is set to 0 then the capture instance drops the table cdc_stop_on_breaking_schema_changes is set to 1 then the CDC will capture the data for the existing columns ignoring the new columns Action steps: If the property cdc_stop_on_breaking_schema_changes is set to 1, if schema changes are to be applied 1.Backup the existing CT table and the cdc_state table 2.Drop the source table from CDC instance 3.Add the CDC instance with the altered source table 4.Import the historical data from CT to the new capture instance 5.Modify the SSIS package to capture the new column for initial and incremental load from the last LSN |
| Drop an existing column from the source table | Impact: If the cdc_stop_on_breaking_schema_changes is set to 0 then the capture instance drops the table cdc_stop_on_breaking_schema_changes is set to 1 then the CDC will stop data capture with an error Note: A column is dropped on source table only if the supplemental logging on that table is dropped Action Steps:If the property cdc_stop_on_breaking_schema_changes is set to 1, if schema changes are to be applied 1.Drop the supplemental logging on the source table 2.Drop the column on source table 3.Backup the existing CT table and the cdc_state table 4.Drop the source table from CDC instance 5.Add the CDC instance with the altered source table 6.Import the historical data from CT to the new capture instance 7.Modify the SSIS package to capture the new column for initial and incremental load from the last LSN |
| Rename an existing column on the source table | Impact: If the cdc_stop_on_breaking_schema_changes is set to 0 then the capture instance drops the table cdc_stop_on_breaking_schema_changes is set to 1 then the CDC will stop data capture with an error Action steps: If the property cdc_stop_on_breaking_schema_changes is set to 1, if schema changes are to be applied 1.Backup the existing CT table and the cdc_state table 2.Drop the source table from CDC instance 3.Add the CDC instance with the altered source table 4.Import the historical data from CT to the new capture instance 5.Modify the SSIS package to capture the new column for initial and incremental load from the last LSN |
| Change in data type or data type length on the source table | Impact: If the cdc_stop_on_breaking_schema_changes is set to 0 and if data type is changed from for e.g. int to varchar then the capture instance drops the table cdc_stop_on_breaking_schema_changes is set to 1 then the CDC will do below 1.If the data type change is from for e.g. varchar to int, then NULL value is captured although different row operations state (3 & 4) are logged 2.If the data type length is changed then row operation state 3 is alone captured Action steps: If the property cdc_stop_on_breaking_schema_changes is set to 1, if schema changes are to be applied 1.Backup the existing CT table and the cdc_state table 2.Drop the source table from CDC instance 3.Add the CDC instance with the altered source table 4.Import the historical data from CT to the new capture instance 5.Modify the SSIS package to capture the new column for initial and incremental load from the last LSN |
A schema change on the source table should be applied on the business tables through a series of steps and procedure to capture accurate and consistent data.
CDIs-Non Functional Requirements-Other few May 21, 2013
Posted by msrviking in Architecture, Business Intelligence, Data Integration, Design, Integration, Security.Tags: architecture, CDI, Data Hub, Design, Extensibility, Maintainenance, NFR, Non Functional Requirement, Others, Security
add a comment
In the series of CDIs-Non Functional Requirements I had covered on NFRs like Performance, Scalability, Availability, Reliability, and Utilization Benchmarks that could be useful to build a CDI system. In this post I shall talk about less known but important NFRs like Maintainability, Extensibility and Security. I wouldn’t term these as NFRs but questions on these topics will help you to get an insight on how the system is expected to behave, from a business and technical perspective. Also, these don’t work in silos, instead are linked back to some of the ones mentioned in the above list.
Maintainability
-
What is the maintenance/release cycle?
This question will give us an idea on the practices that is followed by the business and technical teams about the release cycle. And each release cycle would mean there would be change in the source system which may be applicable to down-stream applications. The more the release cycles, the difficult is the job of maintaining code base. And to avoid long-term overheads the system, data model and the low level design of the ETLs should be carefully built considering that this changes would be constant, and frequent.
-
How frequently do source or target structures change? What is the probability of such change?
This point is relevant to the first question, but elicits information one level deeper by asking “if more maintenance cycles, what are those changes at source and expected to be in target”. If the changes are constant, frequent and less complex then the data model and the ETLs have to be configurable to accommodate ‘certain’ changes in the source. The configurability comes with a rider and tradeoff on other NFR like performance. The changes on data source could affect the performance of the ETL and sometimes the business laid SLA can’t be met.
Now having said this, I presume the next NFR will be closely related with Maintainability.
Configurability
The answers to queries under this topic is supposedly to be challenging for the business, and technical teams. Not everyone is sure of what should be configurable and what shouldn’t be based on the changes that are expected from business at the source system level. One would get the answer of “not sure”, “may be”, “near future quite possible”, “probably” the source will change, and what change will remain as a question. The challenge of providing an appropriate solution at different layers will be a daunting task for the technical team.
-
How many different/divergent sources (different source formats) are expected to be supported?
The answer to this question will help in understanding what formats of sources (csv, tsv, xml..etc…) have to be supported, and if there is plenty of difference then alternate design practices could be implemented on the target which could provide extensibility to all formats.
-
What kind of enhancements/changes to source formats are expected to come in?
An answer to this point would help in deciding if there be abstract transformations or reusable mappings.
-
What is the probability of getting new sources added? How frequently does the source format change? How divergent will the new source formats be?
This information will help in knowing how often the sources format change, and is it with existing sources or with new ones. Again it would also help in deciding between abstract transformations or reusable mappings.
The last NFR is Security which is usually the last preferred in any system architecture and design, but most important.
Security
In case of CDI we are dealing with sensitive information of the customer and the transaction details. It is important to understand how business treats this type of data, and how do security compliance team want to consider the data is being gathered from different source systems and consolidated at a single place – “Data hub”. The below bunch of questions cover on the data protection level rather than access levels or privileges of different users.
-
Are there any special security requirements (such as data encryption or privacy) applicable?
An answer to this question usually would be “no”, but there are certain fields that are brought in from CRM and ERP systems and needs to be hidden from any misuse in case of breach of security. It is suggested that this question is explained well with a real scenario, and then a decision of having data or database encryption enabled or not could be taken.
-
Are there any logging and auditing requirements?
This is least required since the data from different systems is mostly massaged and made available in reporting format through a different data sink. A discussion in here would help in deciding if the security should be handled at reporting level (enabling different security features), rather than in massive data processes.
I hope all these posts on NFR for CDIs helps you in architecting, designing Data Hub system that is highly available, scalable, high performing, and most reliable.
Cheers!
